.png)
This post continues from the previous post: Towards 2-Dimensional State-Space Models (1): Intro.
Once we accept the separation of the sequence construction order and the spatial coordinates , we can consider wide range of image transformations that align much better with inherent image properties.
Few transformations that would come to your mind would be:



Then, what’s next? Can we construct SSMs on this?
A generalized view of SSMs
I spent quite a lot of time thinking about ways to derive a valid SSM on this concept. I started from HiPPO (Gu et al., NeurIPS 2020), since that’s where the 1D SSMs are built upon.
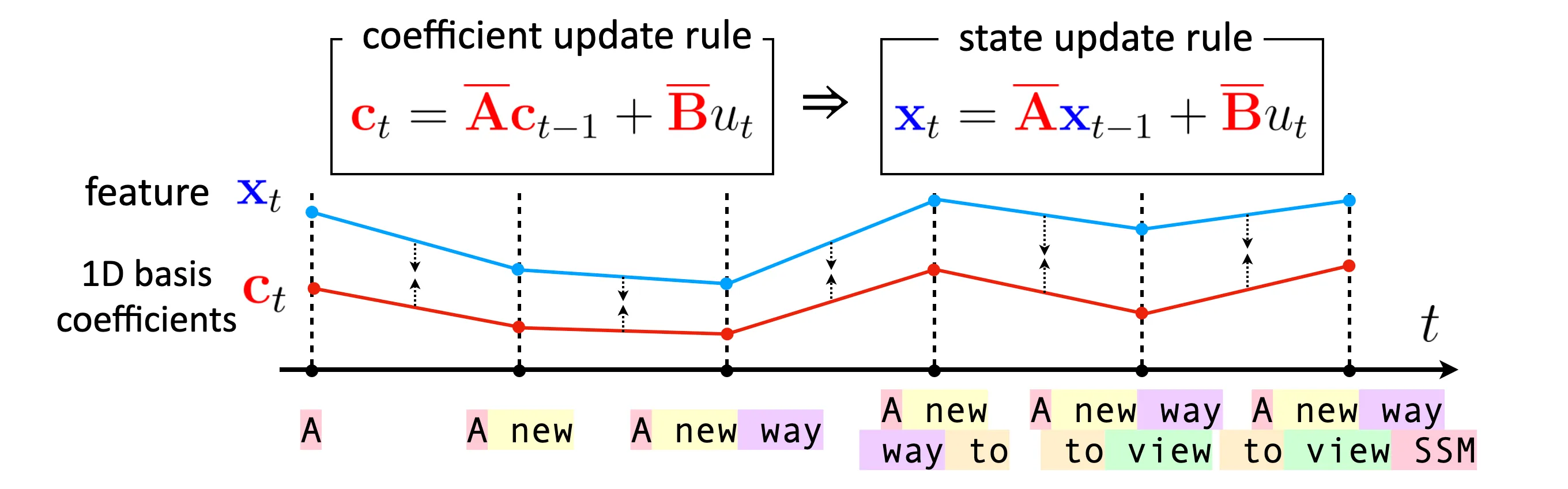
To briefly explain, HiPPO manually derived the dynamics of orthogonal polynomial coefficients that reflects the newly added token , and let the RNN’s hidden update follow this dynamics, as described in the figure above. I provide you more detailed explanation in my previous post.
At the end, I figured that SSMs are implicitly nudged to follow designated compression function (or basis projection, for mathematical ease) that we choose in the first place. Let me explain this in a more principled way.
In my opinion, the mechanisms of existing SSMs can be characterized by two components:
- a compression function ,
- an input transformation , where denotes the input at time .
With this setup, we can explain pretty much of the existing SSMs, either 1D or 2D.
For example, HiPPO chose the compression function as a projection using 1D orthogonal polynomials, while choosing the input transformation as a concatenation of the -th token next to the 1D input at time .
Letting be the projection using 2D orthogonal polynomials and be the corner-based construction using 2-dimensional sweeping will coincide with the formulation introduced in S4ND or 2D-SSM.
In fact, we can regard that the hidden states of SSMs are trained to resemble the behavior of compression function in an indirect way; by mimicking its dynamics on the predefined input transformation , rather than mimicking its actual outputs.
This somehow explains where the compactness—the well-known ability of SSMs—emerges from: it may be due to its inherent design pushing the hidden state to resemble the compression function . To step a little further, if you choose a typical basis function projection as , you can expect the hidden state to capture spectral components of the input, as one of the properties that a lot of basis projections have is the decomposition of the input into spectral components. With this approach, you can distill favorable properties of to the hidden state, which has been an effective strategy for SSMs.
Thus, if we choose a combination of compression function and input transformation and enforce a feature to follow the update rule induced by , we can come up with a novel SSM formulation that inherits the SSM’s core strategy.
WHippo: finding a good combination

: 1D scanning
: 1D OP projection

: 2D scanning
: 2D OP projection

: Gaussian blurring
: 2D OP projection
The illustration above shows the choice of with designated compression function .
One thing to note when choosing and is to ensure that the update is tractable: the dynamics of compressed representation must be computable without having to decompress the input. This is related to the derive-ability of the derivative , and explains why it is convenient to use basis projection as the compression function ; basis projection is often smooth and differentiable, compared to other compression formats such as PNG or Huffman Coding.
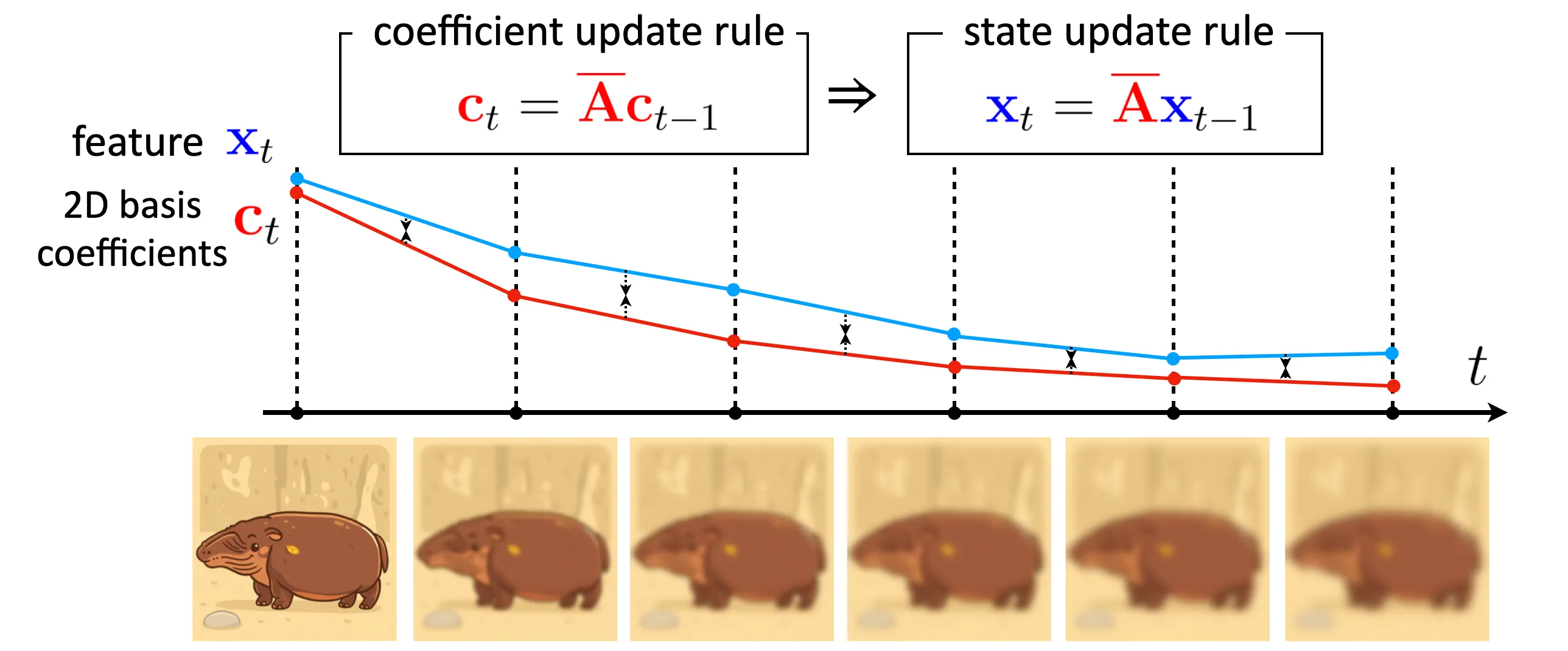
My friend Jaemin and I found that choosing as 2D orthogonal polynomial basis projection and as Gaussian blurring results in a quite simple update rule, and we name this framework, WHippo.
Why named WHippo?

- The biological classification of hippo is called Whippomorpha, which is a class of mammals that includes whales and hippos. So, Whippo can be viewed as a superclass (or generalization) of hippo.
- This idea is a continuation of HiPPO (NeurIPS 2020), which was the starting point of the state-space model, and we are trying to extend HiPPO to 2D, which previously only worked in 1D. Therefore, our HiPPO has spatial dimensions (Width, Height).
Why Gaussian blurring?
TL;DR, the Gaussian kernel provides a lot of really nice properties that align with our visual perception process, and reflects inherent property of natural images as well.
Scale-space theory: A basic tool for analyzing structures at different scales (Tony Lindeberg, 1994; Journal of Applied Statistics) talks about scale-space in images.
Research on finding better ways to analyze a given input at different scales is one of the oldest challenges in computer vision, and this paper is one of the classic theories on this subject. Here they study blurring techniques that allow us to obtain good scale representations and introduce the resulting method.
... This chapter gives a tutorial review of a special type of multi-scale representation, linear scale-space representation, which has been developed by the computer vision community in order to handle image structures at different scales in a consistent manner...
The main result we will arrive at is that if rather general conditions are posed on the types of computations that are to be performed at the first stages of visual processing, then the Gaussian kernel and its derivatives are singled out as the only possible smoothing kernels.

In our case, the Gaussian kernel provides a number of good properties in other means as well. The Gaussian kernel is defined in a continuous manner, is deterministic, and preserves linearity (applying two Gaussian kernels of and results in applying a single Gaussian kernel of ). This largely helps our derivation of later.
Derivation of the WHippo update rule
Hence, our next step would be to derive the update rule based on the chosen .
The figure aboveShow information for the linked content already spoils how the update rule looks like: it actually ends up inducing a pretty simple rule:
with a structured matrix .
Below I provide the derivation process of the update rule. Hopefully, its derivation process is not as hard as that of HiPPO’sShow information for the linked content.
Let’s assume an image with only one channel and derive the expression.
(although the illustrations show an RGB image)
Here, we assume the image as a surface function rather than a set of discrete points, which makes our formulation perfectly analogous to the original 1D SSM’s derivation.

Let a continuous sequence of images with increasingly blurred images be (), where the Gaussian kernel applied at -th timestep is
Then the image can be viewed , where is the convolution operation. We can obtain the coefficients corresponding to the 2D basis functions by projecting an image onto the basis functions:
We are interested in the dynamics of with respect to , so differentiating both sides with respect to gives:
Note that convolution with a Gaussian filter is a well known solution of heat equations.
What does this mean?
Assume a trivariate function , which models how the temperature at each coordinate (on as defined above) changes over time, then the PDE Heat equation (or, diffusion equation) describes the amount of temperature change at each point as follows:
If , the temperature distribution at time (initial value condition), and derivatives at boundaries, , (boundary conditions; we usually let them be zero, following standard Neumann boundary condition) are given, we can find the solution of the above equation. The known solution is . More precisely, it is satisfied when the standard deviation of the Gaussian filter is .
In other words, if we consider the initial value in the image sequence aboveShow information for the linked content to be the temperature rather than the pixel intensity, then the pixels becomes equivalent to representing the temperature after .
is the solution to the heat equation , so the partial differential term appearing in (2) can be summarized as follows:
On the other hand, before computing the above, we can reorganize terms cleaner if we first represent the image of each step as a sum of basis functions . Since we already have defined the coefficients of the basis functions, we can easily use them to express and substitute them:
From here, the derivation can either be easier or harder depending on which basis function you choose.
In general, good basis functions assume orthogonal properties, so the basis function that allows to be expressed with will be the easiest to derive.
(For example, in the case of Fourier, is a scaled term, so we can expect a very clean expression!)
The final expression:
The good news is that we actually already have an expression that looks like a simple form of the SSM. Since the change in is expressed as a linear combination of different ’s, this can be understood as a matrix operation:
The WHippo matrix
The structure of the matrix is solely dependent on the choice of the 2D basis function .
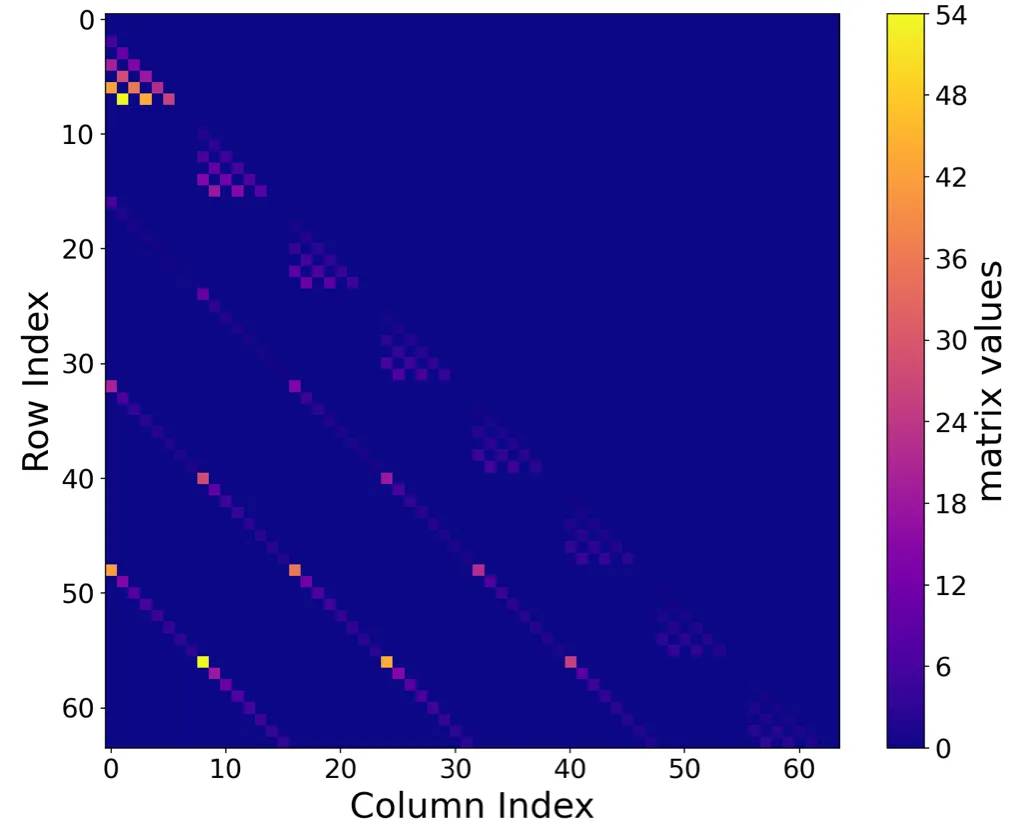
I’ll skip the derivation of matrices for different bases, but I think it is worth sharing how they look like. Below are figures of those matrices, and you can see their sparse structures.
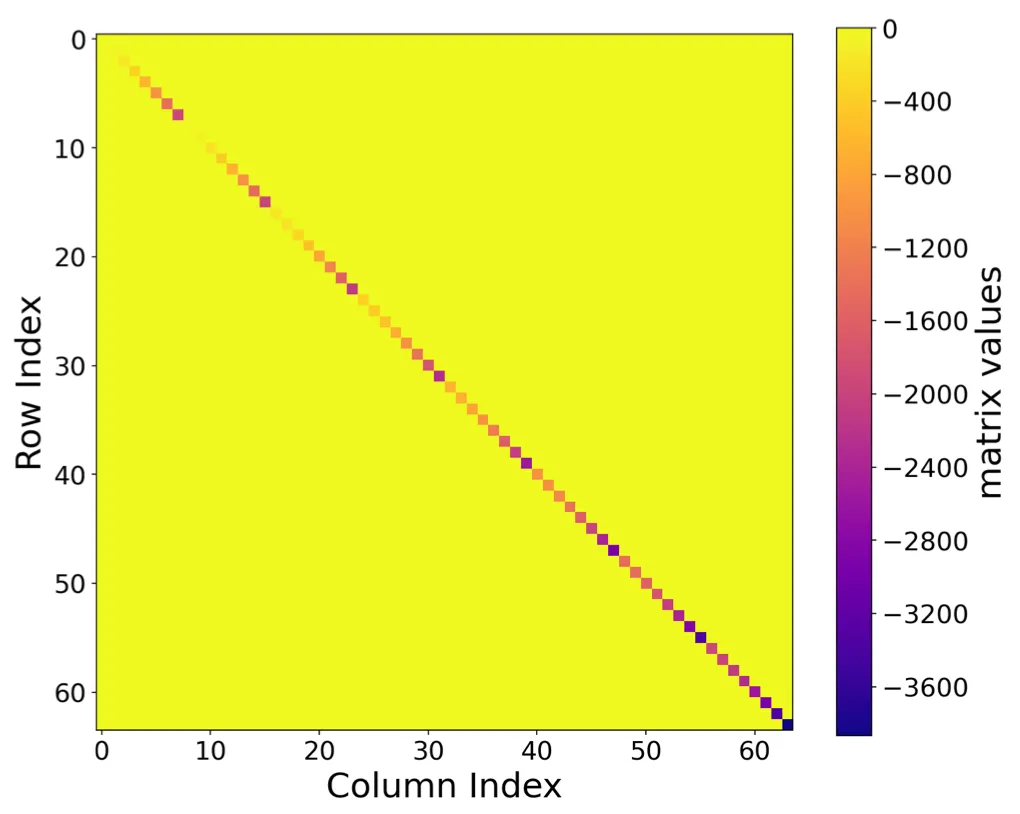
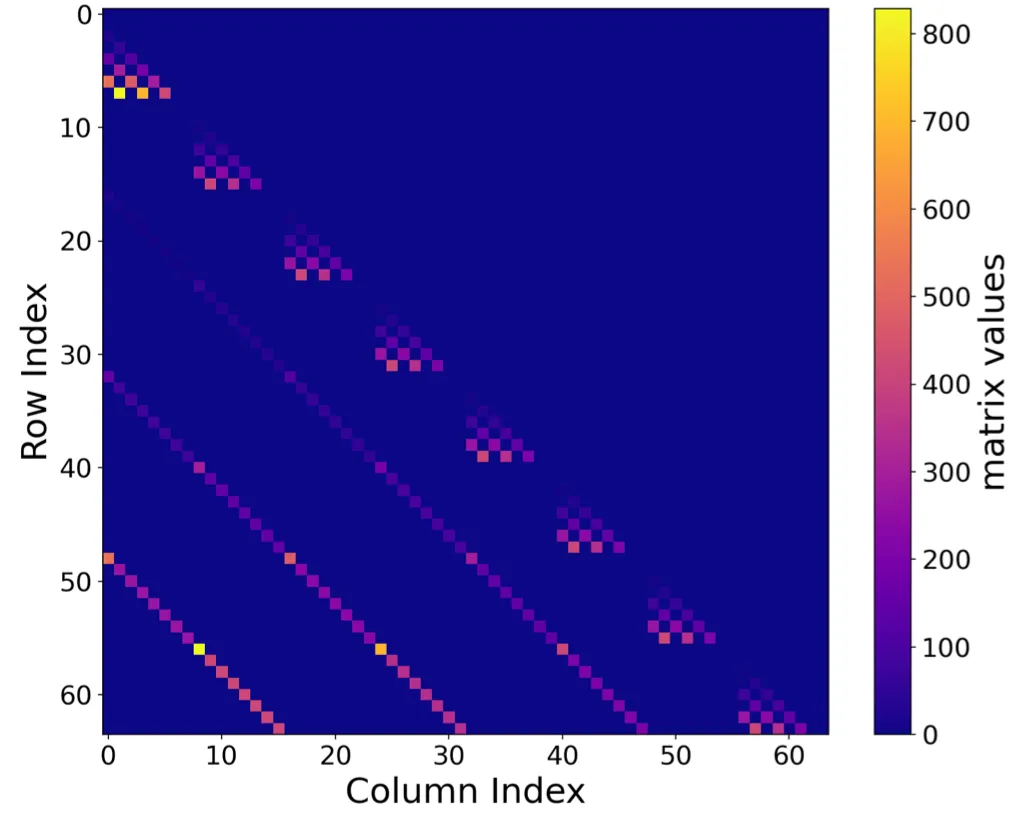
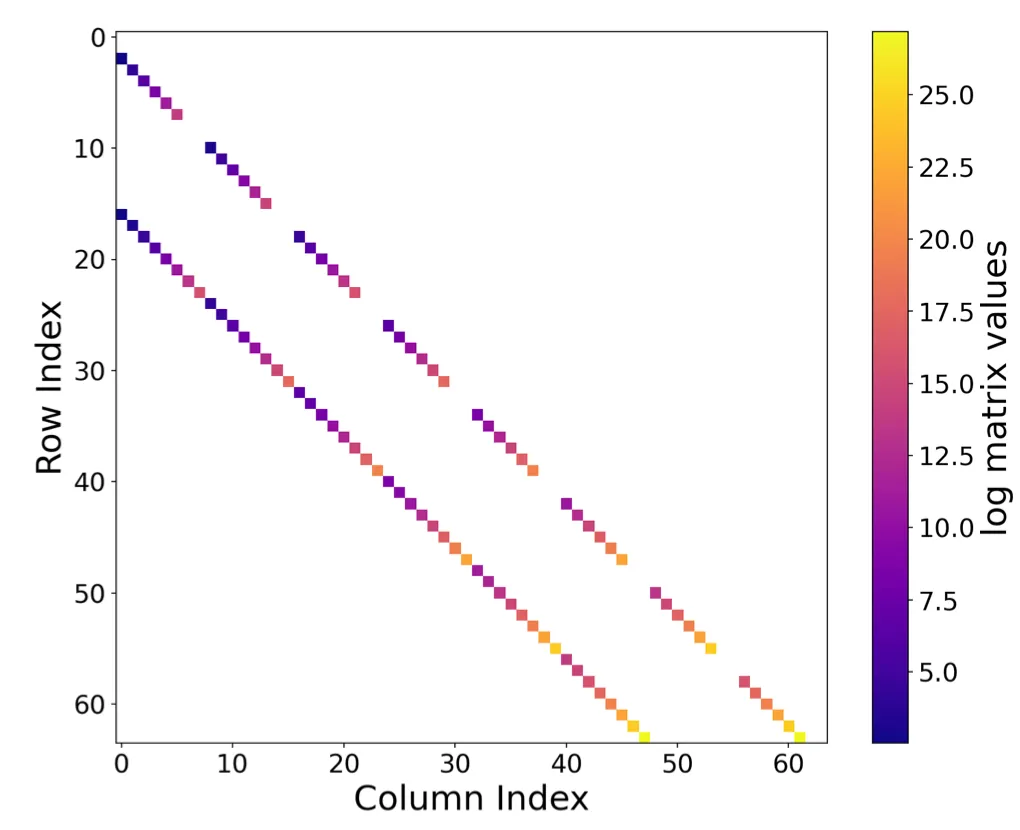
One particularly interesting observation is that choosing Fourier bases projection as naturally yields a diagonal matrix , which has long been preferred in 1D SSMs due to its simplicity of computing matrix powers. Regarding that numerous studies have been devoted to simplifying S4’s diagonal-plus-low-rank (DPLR) formulation by removing the low-rank correction in order to enjoy the efficient and simplified nature of diagonal matrix, it is quite intriguing that a diagonal form of emerges here for free: we do not rely on any approximation, nor do we need to empirically justify whether the resulting parameterization is expressive enough.
Little caveats from the diagonal WHippo
Looking into details of Fourier-based diagonal WHippo tells us some more interesting facts.
The -th diagonal values of is
where and .
To provide a concrete view, I visualized the matrix where :
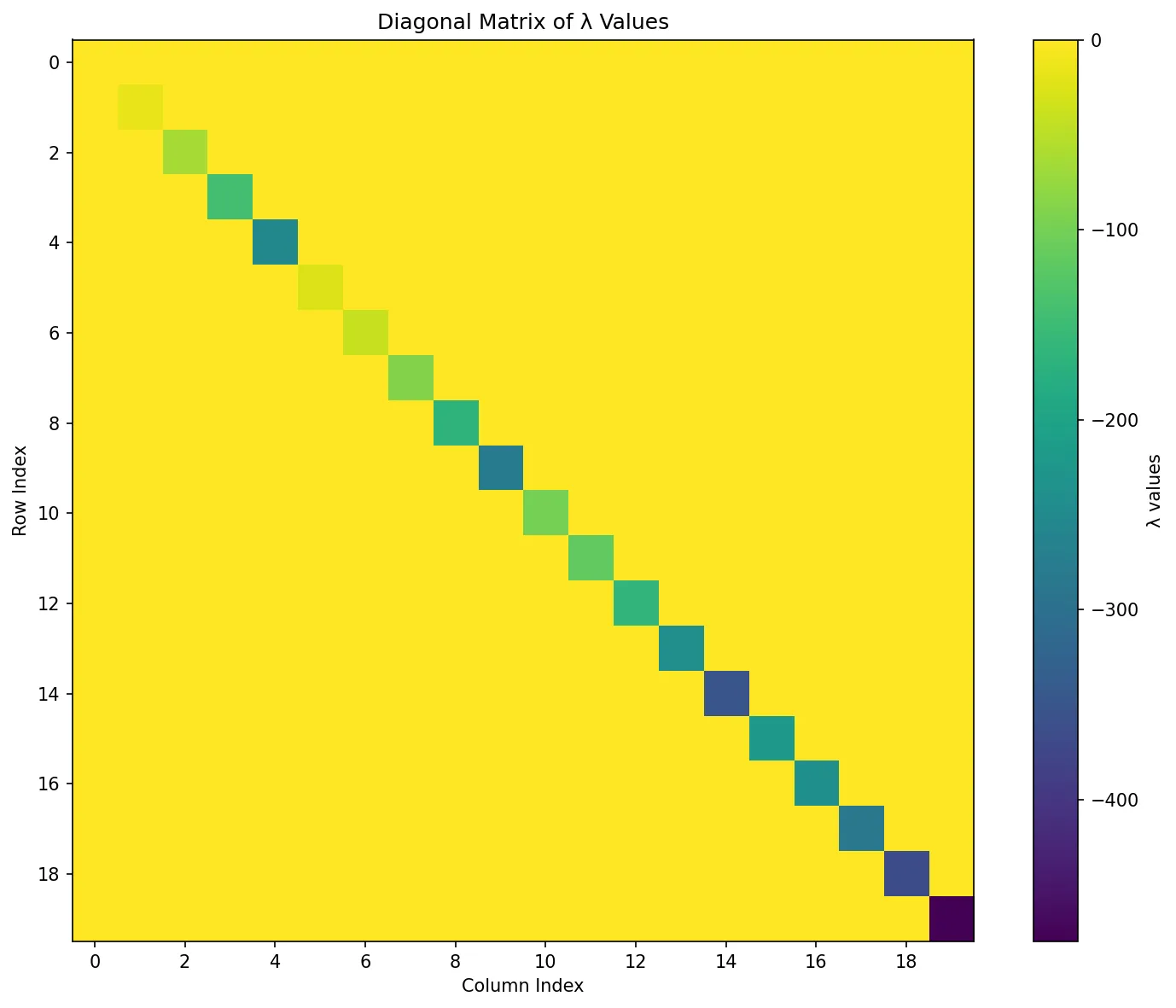
Here, we observed two caveats that are worth to discuss.
- Every is a negative real value, as S4D and SaShiMi propose: (from S4D)
Note that the kernel blows up to as if has any eigenvalues with positive real part. Goel et al. found that this is a serious constraint that affects the stability of the model, especially when using the SSM autoregressively. They propose to force the real part of to be negative, also known as the left-half plane condition in classical controls, by parameterizing the real part inside an exponential function .
The main reason for s being parameterized negative was for training stability. The diagonal WHippo matrix already provides such a well-initialized , without having to engineer this property into the model.
- It resembles how Mamba’s diagonal matrix is initialized… but in two dimensions!
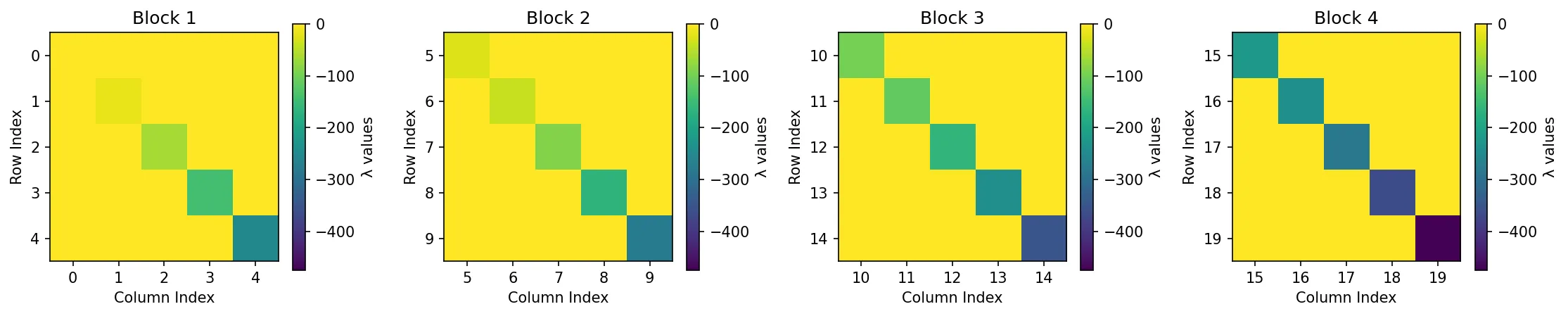
When we group diagonal elements into -sized blocks, we can see analogous evolutions across the blocks. According to Eq. (3)Show information for the linked content, the values grow in a squared scale across both dimensions and .
I strongly believe that there is a connection between ours and S4ND, as this way of multi-dimensional initialization resembles how S4ND constructs SSM kernels using cross-product.
Comparing this to the Mamba ’s (or, S4D-Real’s) initialization, we can find an interesting resemblance again:


Mamba initializes its diagonal elements by assigning incrementally decreasing negative integers: , and each block of Show information for the linked content shows the similar tendency. If we really do want to stick to the Mamba’s legacy, one might be able to do so by initializing the first block matrix’s diagonal elements as and the next block’s as , yielding a natural multi-dimensional generalization.
🔎The tradition of increment is derived from setting as legendre polynomial in the previous studies. We also observed that deriving the matrix from legendre polynomial gives a matrix with a very stable scale, linear to the matrix size : see Legendre Show information for the linked content, and you can observe that it is the only case where the matrix values are on a pleasant scale. Other than that, we could not find more meaningful insights yet.
So, what’s next? Any use of this?
Now we derived a novel 2D SSM formulation that is more natural in terms of image processing.
Then, how can this be implemented in neural network training?
I’ll explain its intriguing usage in the next post. To tease a little bit, there was an unexpected property that this framework provides to diffusion modeling!