Why does classification matter in video action detection?
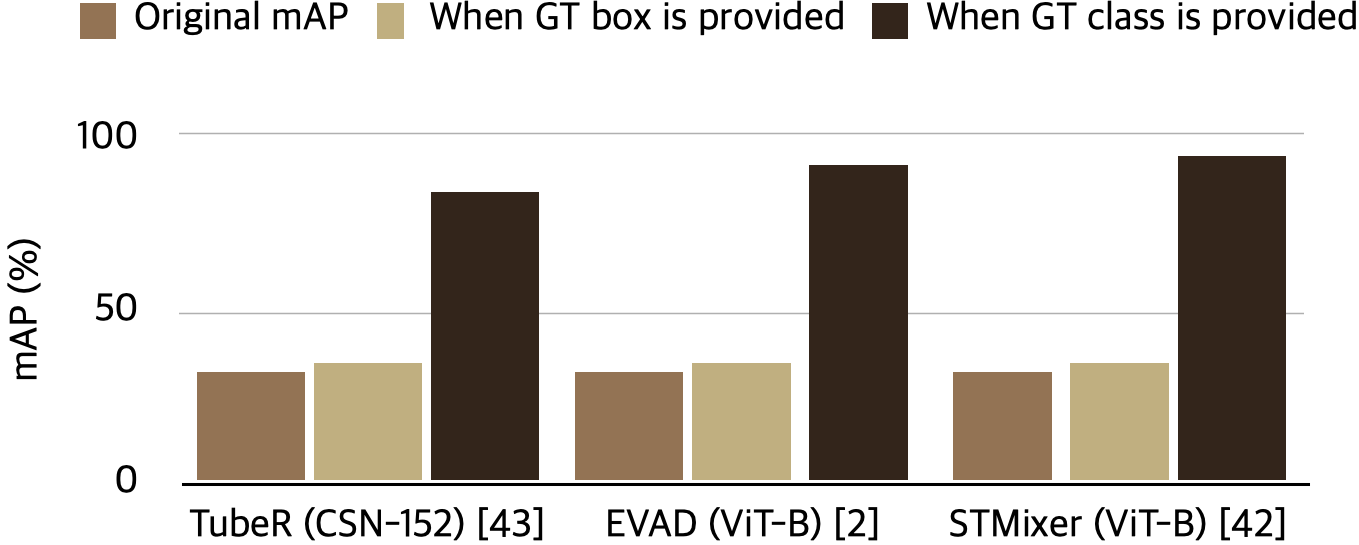
Video action detection (VAD) inherently holds difficulties of accurately classifying an action rather than localizing, since the instances appearing in datasets are always human. The graph above shows how important the classification is; providing GT class labels improves the performance way more than providing GT box labels does.

We discovered that previous state-of-the-art methods often failed to capture the correct context that corresponds to the performed actions. They particularly avoided browsing outside the actor region no matter what actions were being performed. It is somehow a natural behavior, since most models utilize a single attention map for each actor and gather semantics that are useful for classification, which drives a model to prioritize capturing commonly-shared semantics among classes: the actor. Intrigued by such observation, we propose to generate an attention map for each class, so that the model could explicitly focus on class-specific context rather than utilizing an actor-biased, ambiguous classification attention map.
Model Architecture
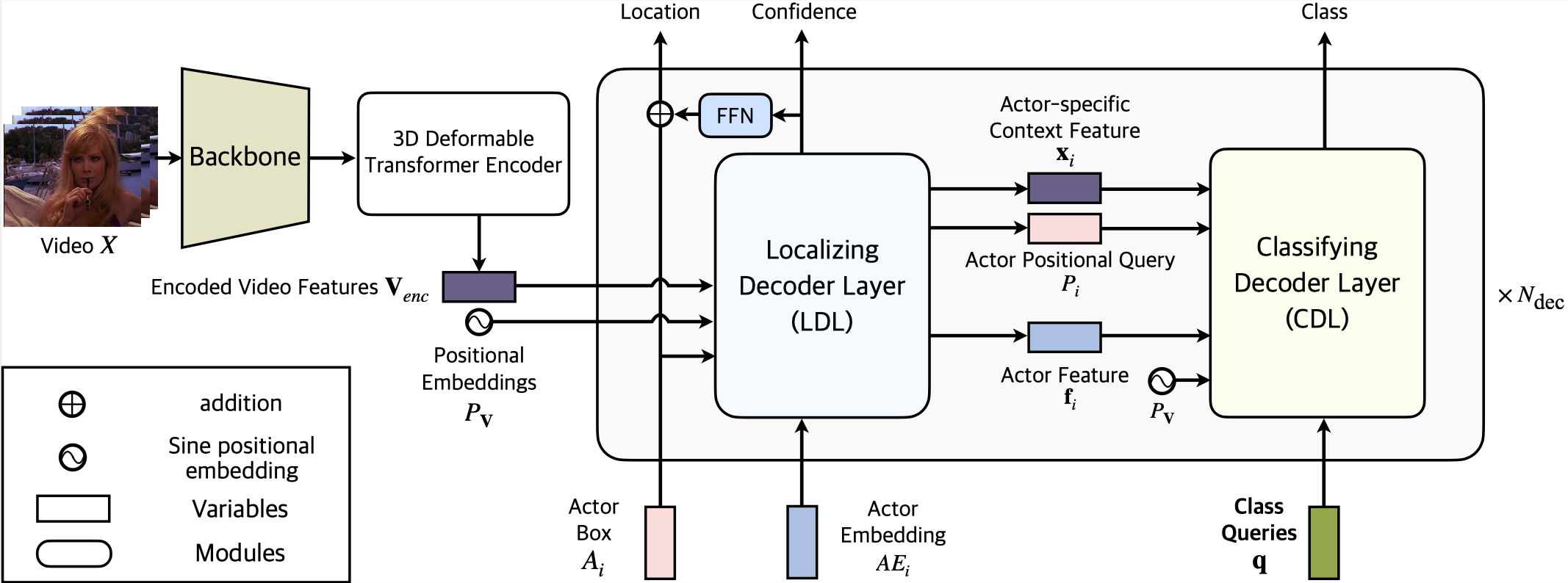
We propose three modules, 3D Deformable Transformer Encoder, Localizing Decoder Layer (LDL), and Classifying Decoder Layer (CDL). Input videos are processed through backbone and 3D Deformable Transformer Encoder to obtain video features. LDL focuses on localizing the actor, and hands the actor-related features over to CDL. Our classification module, CDL, processes the actor feature, context feature and class queries to obtain class-specific attention map. To be specific, it first merges the actor feature and the context feature and then cross attend the merged feature with class queries. The model finally aggregates the class-wise information from each map and outputs final logit for each actor.
Experiments

The proposed model surpasses or is on par with conventional VAD benchmarks: AVAv2.2, JHMDB51-21, and UCF101-24.
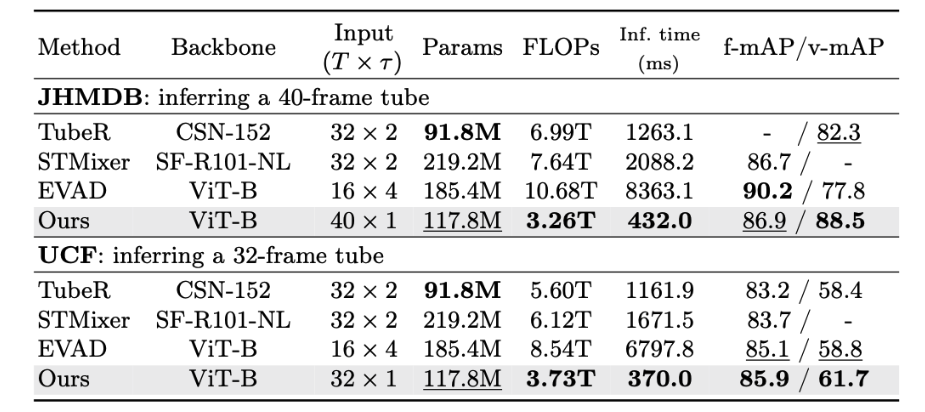
Since our model can generate a number of various attention maps for each actor candidate, it reaches greater performance with fewer actor candidates. This eventually results in lower memory/parameter usage, so we utilize the remaining memories to enable the model to output multiple frame with a single inference. The efficiency comes from such framework is remarkable.
Visualizations

The input image (left) and the corresponding classification attention maps (right) for each actor (discerned by color) and each action class

The input image (left) and the corresponding classification attention maps (right) for each actor (discerned by color) and each action class
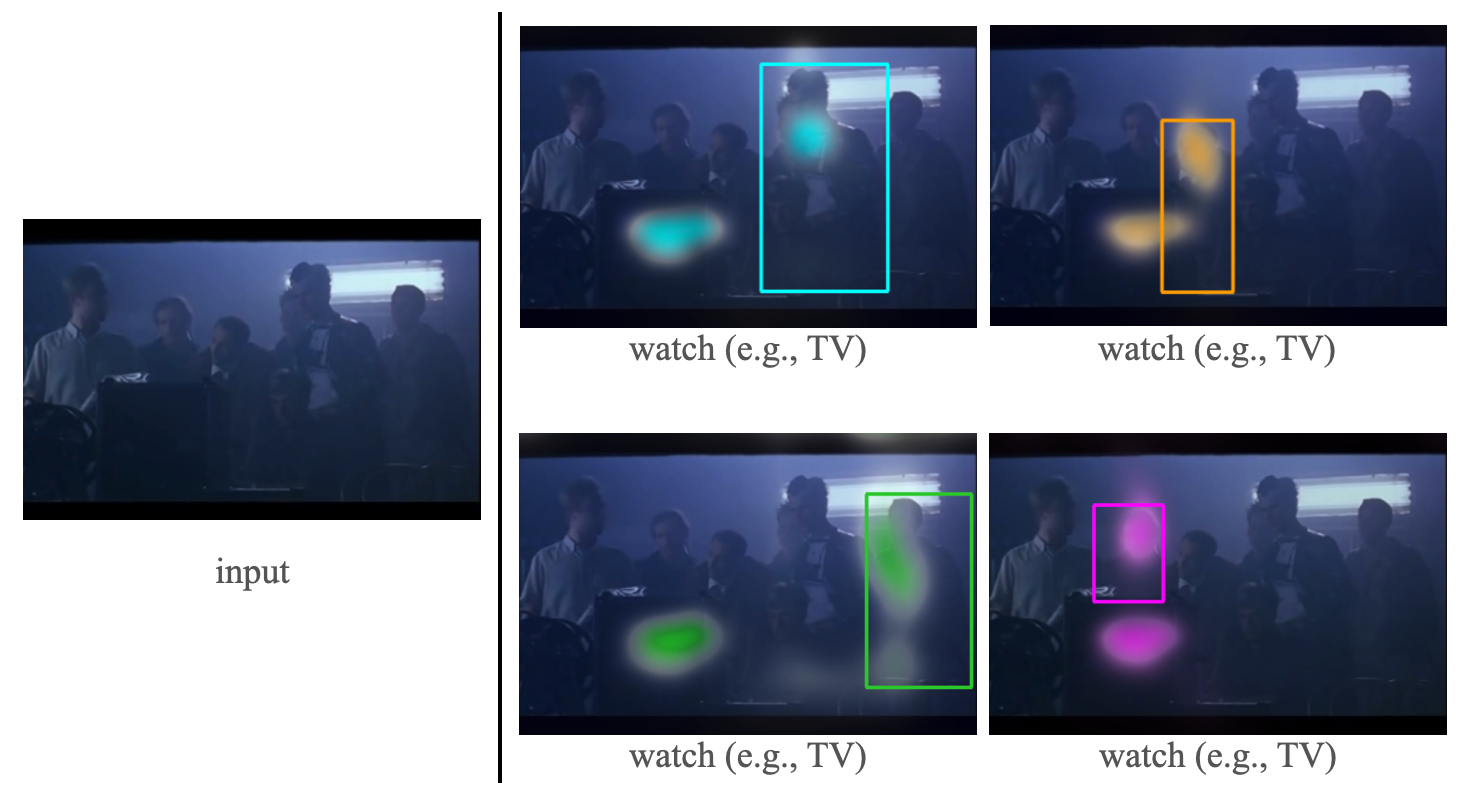
The proposed model captures actor-specific class context well even when multiple actors perform identical actions.

The proposed model captures actor-specific class context well even when multiple actors perform identical actions.
Other detection results
Video presentation
Poster
BibTeX
@inproceedings{lee2024classification,
title={Classification Matters: Improving Video Action Detection with Class-Specific Attention},
author={Lee, Jinsung and Kim, Taeoh and Lee, Inwoong and Shim, Minho and Wee, Dongyoon and Cho, Minsu and Kwak, Suha},
booktitle={European Conference on Computer Vision},
pages={450--467},
year={2024},
organization={Springer}
}