.png)
Hi, I’m Jinsung
I am currently a Ph.D candidate at POSTECH CVLab (Advisor: Prof. Suha Kwak), where I am having fun doing research!
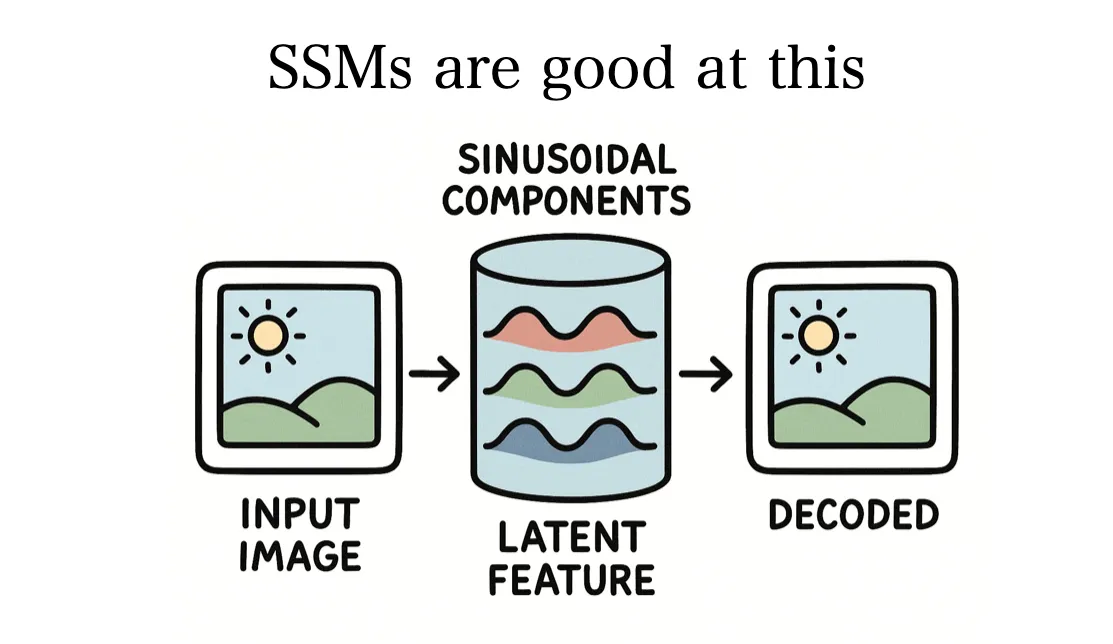
I am interested in designing a compressive neural networks that extract the most informative features within a fixed space of limited complexity. I believe that state-space models (SSMs) offer valuable properties for achieving this goal, and I am actively exploring their application in my work. Previously, I worked on video understanding tasks, such as human action recognition and long-term context modeling. Find my CV here (last updated: Jan 28, 2026).

Updates
Jan 27, 2026
Exploring State-Space Models for Data-Specific Neural Representation
A paper on state-space model has been accepted to the International Conference on Learning Representations (ICLR) 2026.
Nov 8, 2025
Improving Target Presence and Plurality Recognition for Generalized Referring Image Segmentation
A paper on referring image segmentation has been accepted to the AAAI Conference on Artificial Intelligence (AAAI) 2026.
Past notices
Sep 9, 2025
Planning in 16 Tokens: A Compact Discrete Tokenizer for Latent World Model
A paper on compact tokenizer for world model has been accepted to the Conference on Robot Learning Workshop (CoRLW) 2025.
Aug 17, 2025
From HiPPO to Mamba: A Beginner’s Guide to State-Space Models
A new blog post that shares my understanding of State-Space Models (SSMs) has been released!