.png)

Since I started to study state-space models (SSMs) deeply, I’ve been struggling sorting out proper ways to make use of it in the vision domain.
To provide a little context behind my struggle; SSMs are mainly built to transform a 1D sequence into another 1D sequence:
where is the length of input/output sequences, and is their channel size.
One of the most popular neural network architectures today—the Transformer—is also a sequence-to-sequence model. It has proven remarkably effective not only in 1-dimensional domains such as text and audio, but also in multi-dimensional domains, most notably computer vision.
As state-space models (SSMs) began to emerge as a potential alternative to transformers, a natural question followed: how well would SSMs work in the vision domain?
Somewhat surprisingly (and encouragingly), the answer turned out to be: pretty well.
But the way SSMs are implemented was… in fact, not that great in theoretical sense.
Remember how 1D transformers are extended to multi-dimensional settings?
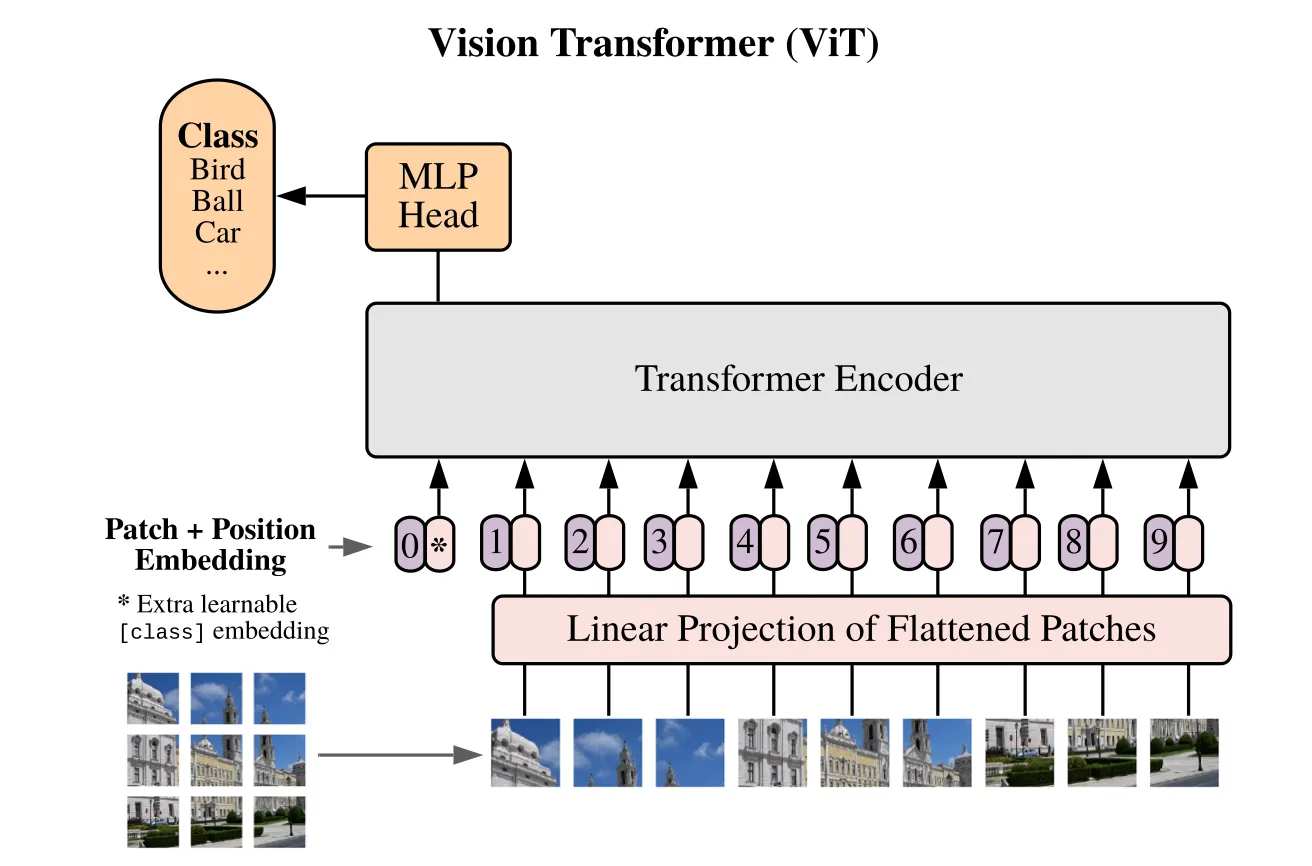
It followed a somewhat naïve approach: the input image is simply patchified, and the resulting patches are arranged into a sequence using a raster-scan order. At first glance, this may feel overly simplistic—but it actually aligns well with the nature of transformers.
Transformers are inherently permutation-invariant: in principle, the absolute position of a patch in the sequence does not matter, since self-attention can still learn which tokens should attend to each other (this is precisely why positional embeddings are needed).
However, how things work in SSMs is not as simple.
Here, the order of elements in the sequence significantly affects the output, making the network permutation-variant. To some extent, it removes the need for positional embedding— which is good—but it leads to a quite unpleasant conclusion: you’ll encounter different outcome every time you change the way you order the patches. This will further make one wonder which order is the optimal way for SSMs to understand images, and it means one needs to explore up to possibilities! By any means, I don’t think it’s the most beautiful way to utilize SSMs for vision tasks.
Though, no clear solution to this has come up yet, and explorations for “scanning methods” became prevalent in the literature.
Some examples with brief explanations and figures of how those methods “scan” multi-dimensional inputs to feed SSMs.
- Vision Mamba (ICML 2024)
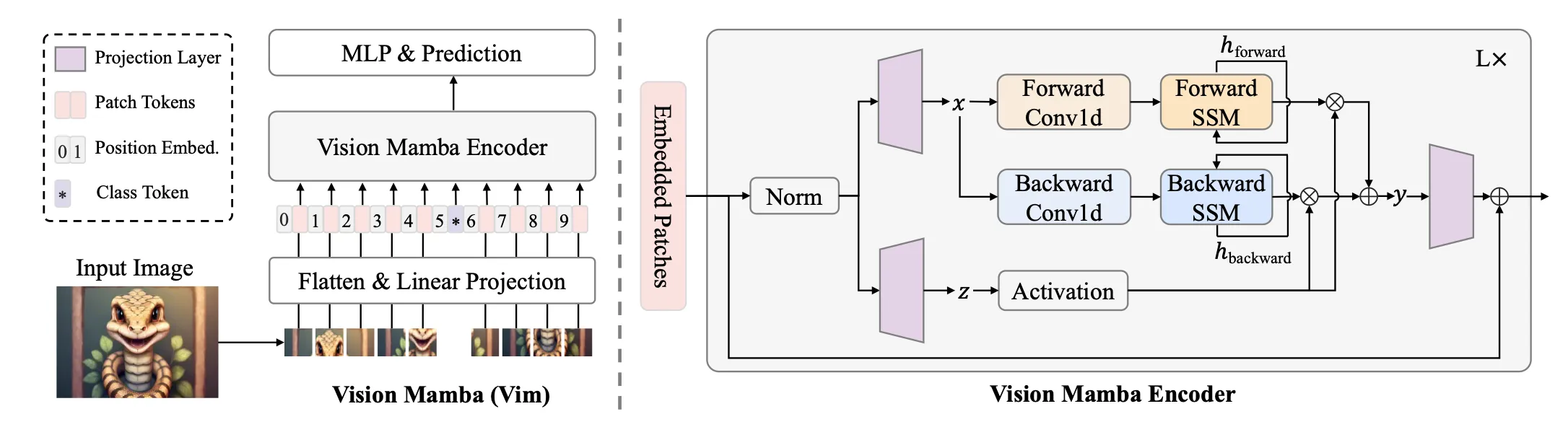
VisionMamba adopts forward and backward raster-scan order. - VideoMamba (ECCV 2024)
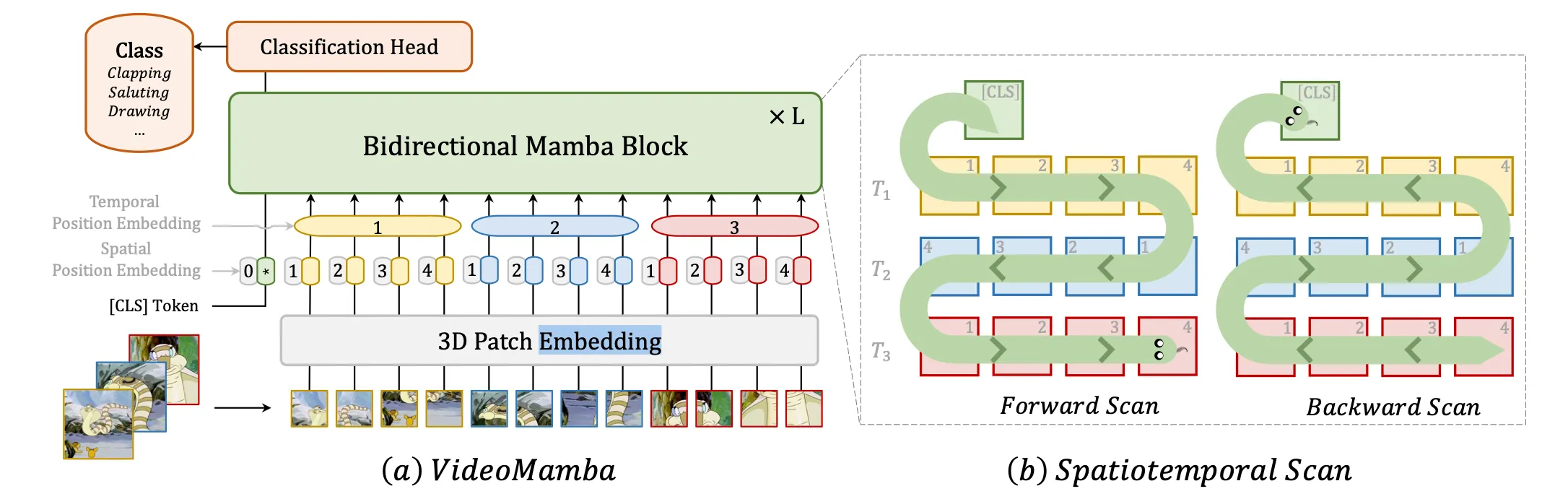
VideoMamba sweeps back and forth over video frames to ensure continuity between tokens. 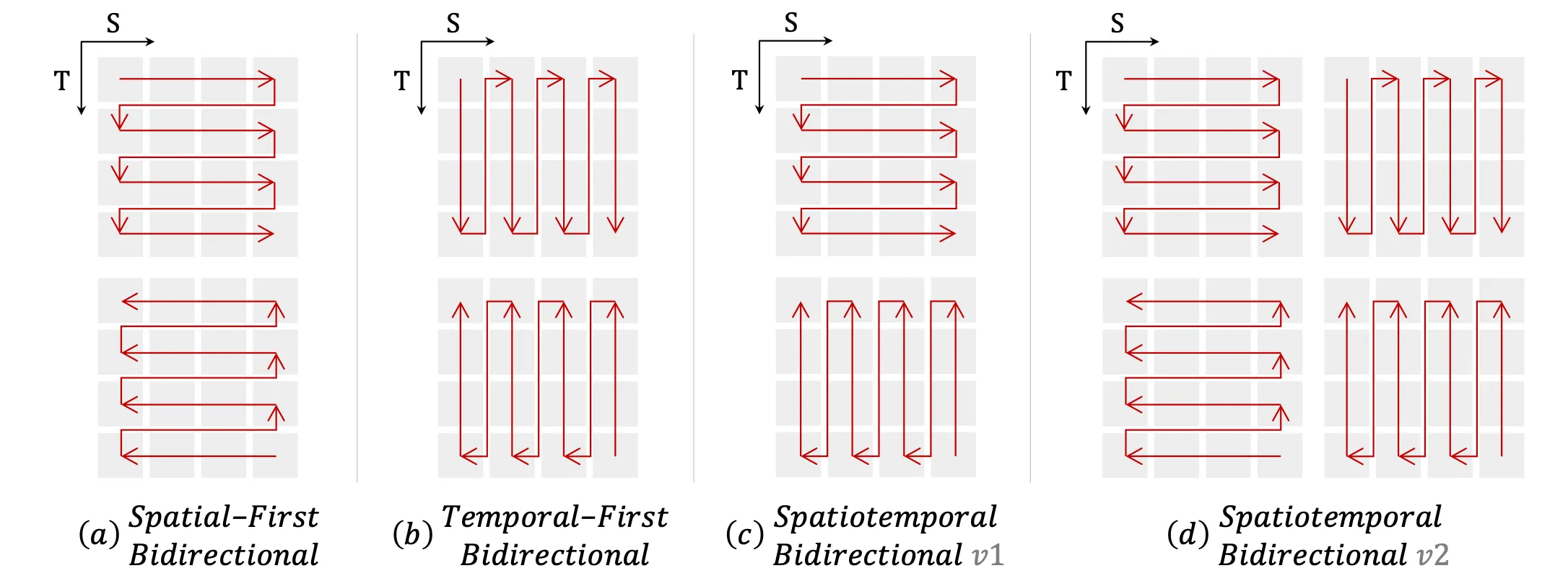
which in fact, is a result of tedious explorations. - ZigMa (ECCV 2024)

ZigMa offers a SSM block that incorporates 8 different zigzag patterns. 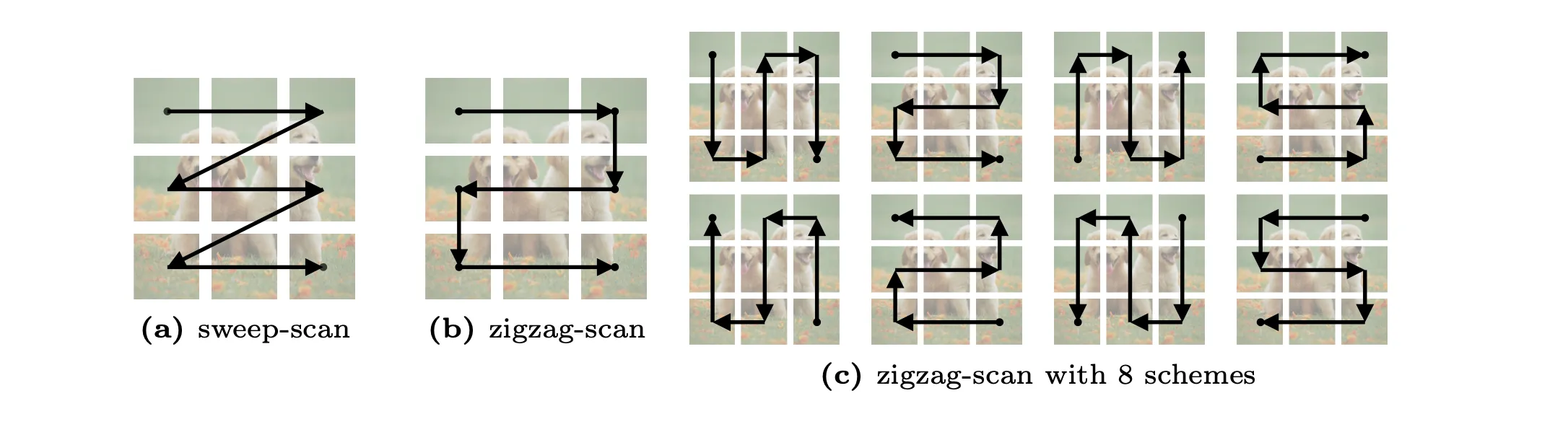
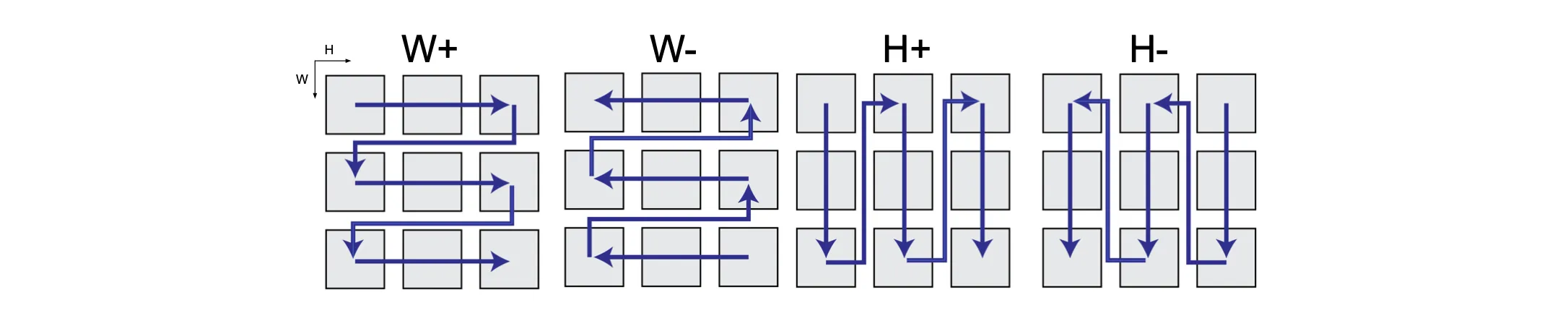
Endeavors to make sure Mamba to understand 2D spatial prior. - MambaND (ECCV 2024)
Similar approach as Zigma. - PointMamba (NeurIPS 2024)
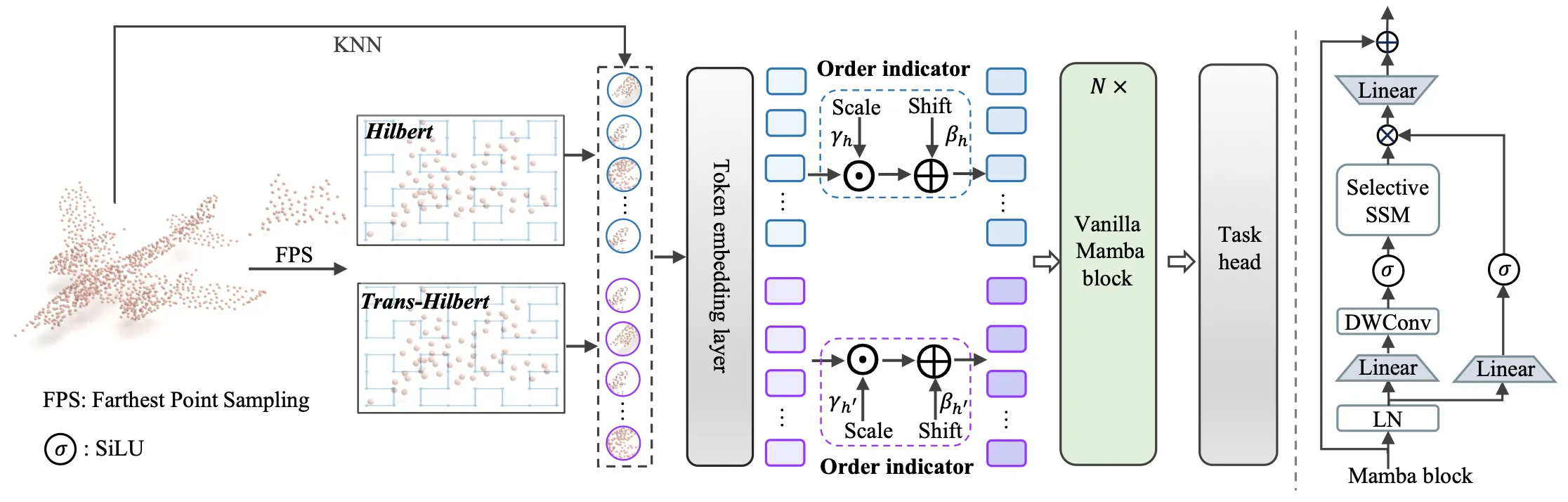
PointMamba comes up with ways to scan points in 3D space.
These studies have produced somewhat counter-intuitive results that encoding data through unnatural scanning is effective, achieving SOTA performance in their respective domains.
I believe these results serve as empirical evidence that Mamba can indeed handle multi-dimensional inputs reasonably well even when they are flattened into sequences—especially when the model is sufficiently scaled up.
At the same time, this also suggests an important caveat: learning to interpret such flattened representations requires additional effort from the model. In practice, this means more parameters, longer training, or slower convergence, since the model must first learn a non-native way of understanding spatial structure rather than benefiting from it directly.
More proper ways to create SSMs that work on multi-dimensional inputs
Since these methods turned out to perform quite decently, they have raised the expectation of how much better a properly scaled N-D SSM could perform.
In fact, such awareness is not completely new, and there have been endeavors to design proper ways to implement SSMs on multi-dimensional inputs.
Two of the most prominent studies that I found proper are followings.
- S4ND (NeurIPS 2022) was the first study to introduce a method for handling N-dimensional data with SSMs without using scanning. Based on the idea that the outer product of N 1D basis functions can be applied as N-D basis functions, the authors created an SSM kernel that can be applied to multidimensional data.
- A 2-Dimensional State-space Layer For Spatial Inductive Bias (ICLR 2024) started from a similar motivation, creating a 2D state-space layer that receives multiple data points in a specific order.
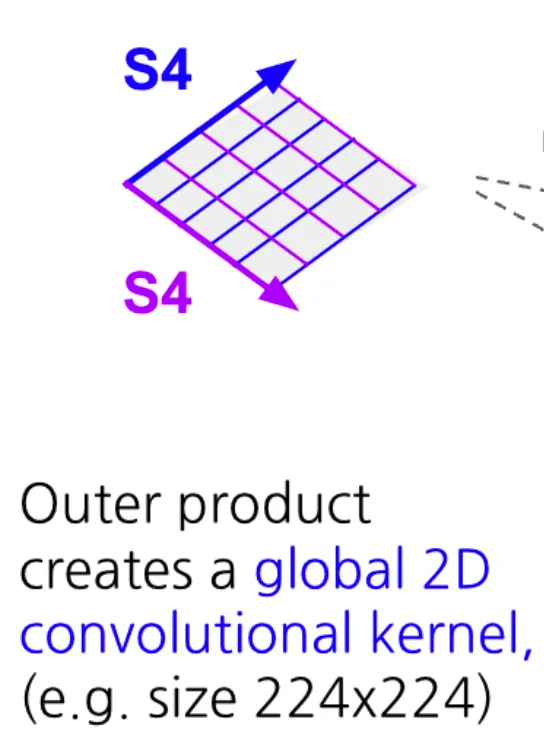
These methods focus less on naively applying existing 1D SSMs to multi-dimensional inputs, and more on rethinking the inherent mechanisms of SSMs themselves, leading to genuinely new 2D formulations.
One key advantage of this line of work is that it explicitly reflects spatial inductive bias.
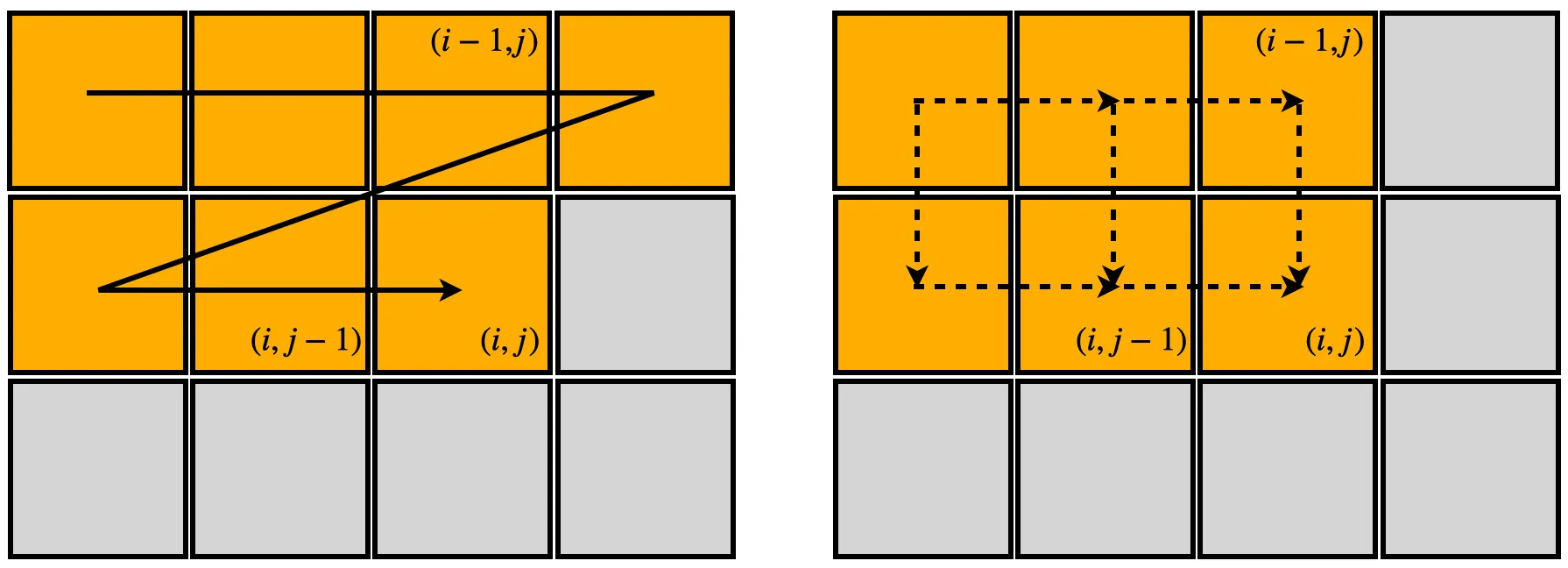
Approaches that rely on flattening an image into a 1D sequence impose a very asymmetric update rule on the hidden state. For instance, with a row-first scan, the hidden state at position aggregates information from all elements in -th row, meaning that information at is always integrated earlier than any element in the -th row.
This ordering is somewhat unnatural for images. Nearby patches tend to be more strongly correlated, yet a 1D scan forces the model to disregard vertical continuity of patches. As a result, such flattening-based methods fail to fully exploit the abstraction capabilities of SSMs.
Since images have two-dimensional redundancies, it is natural to expect SSMs to build more meaningful context when they are allowed to sweep the input along multiple spatial dimensions, rather than being confined to a single, arbitrary ordering.
To put such spatial inductive bias into SSMs, the two methods mentioned above let the hidden state evolve over two dimensions, as shown in the righthand-side figure above.
This indeed makes these methods proper, but we again encounter a similar problem.
From which corner should we start the sweeping?
They may have more mathematical sense than unnatural scanning, but still suffer from having unintended causality that does not exist in images. Hence, at its core, it shares the same problem that the methods that rely on scanning had. As a matter of fact, it necessitates configurations like bidirectional=True to take two corners into account, which can be found in S4ND's source code.
There doesn't seem to be much follow-up research on this line of research yet, except for the arXiv paper Mamba2D (arXiv, 2024).
Then, any better ways to deal with it?
If we think of the problem carefully, we can conclude that this problem cannot be fixed unless we stop mapping coordinates corresponding to in 1D SSMs to those corresponding to , since it eventually ends up creating the order of the tokens that make up the image.
Accordingly, a more ideal 2D SSM, in my opinion, would be not moving of the 1D sequence to -space, but keep as it is. To illustrate what I mean, consider, for example, the following image.

Note that 1D SSMs assume that the entire sequence is built up sequentially, starting from the front. The corresponding process in image space is better thought of as a progressive sharpening process, like VAR (NeurIPS 2024), rather than building up each pixel in a raster-scan order.

The difference with the 1D sequence construction is that this process can be seen as naturally revealing low-frequency information first and filling in the high-frequency information later. Interestingly, this is the distinct character that is not present in the process of building up the next token in text space—which is a good starting point since we want something that is inherent in images.
In the next post, I will introduce a new SSM framework that utilizes such construction.
In the ideation process, I managed to get different insights on SSMs, such as:
- how SSMs happened to have “compactness” in their representations
- an intuitive understanding of the role of the state transition matrix
- even more sound ways to generalize SSMs to operate on N-dimensional inputs
To be continued…