.png)
We extend the idea we previously presented in the CoRL workshop.
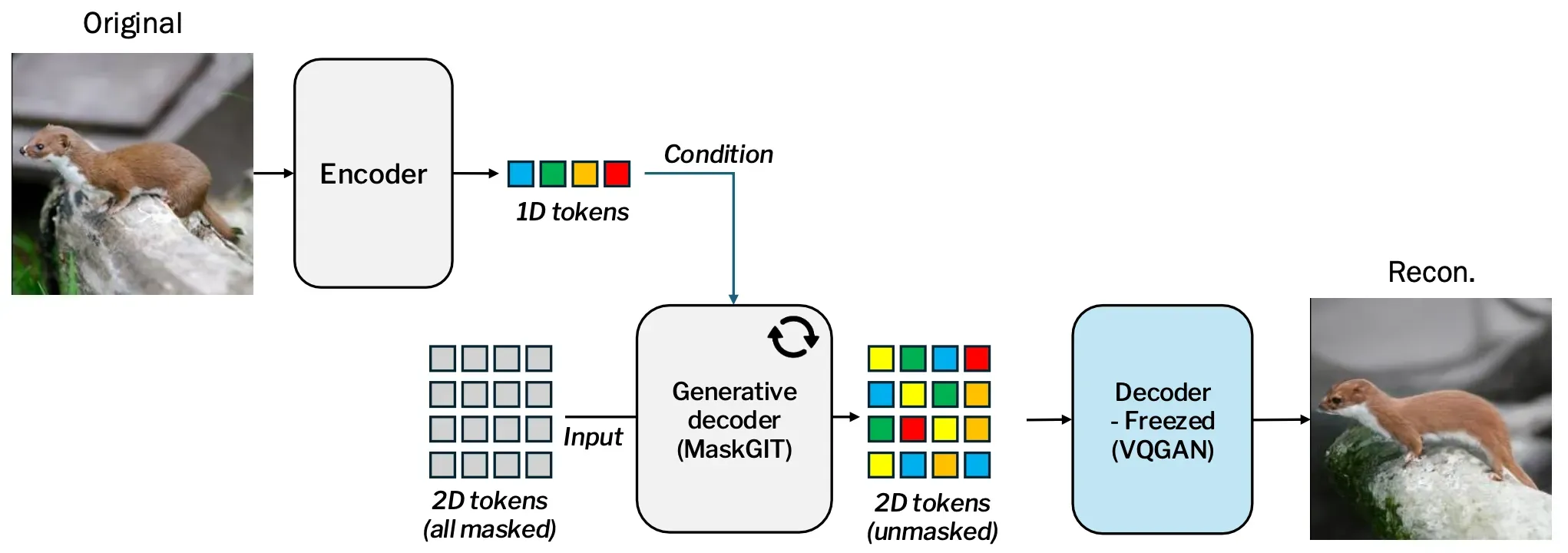
We still stick to the main idea: feature that enables pixel-perfect reconstruction is a bit too much requirements for planning. In this extension, we incorporate vision foundation models (VFMs) to augment our tokenizer to capture semantical element in the image, which resulted in greater performance gain for reconstruction without having to increase the number of tokens. It makes more sense for planning too, since rich semantical features that VFMs provide definitely will help planning-appropriate features!
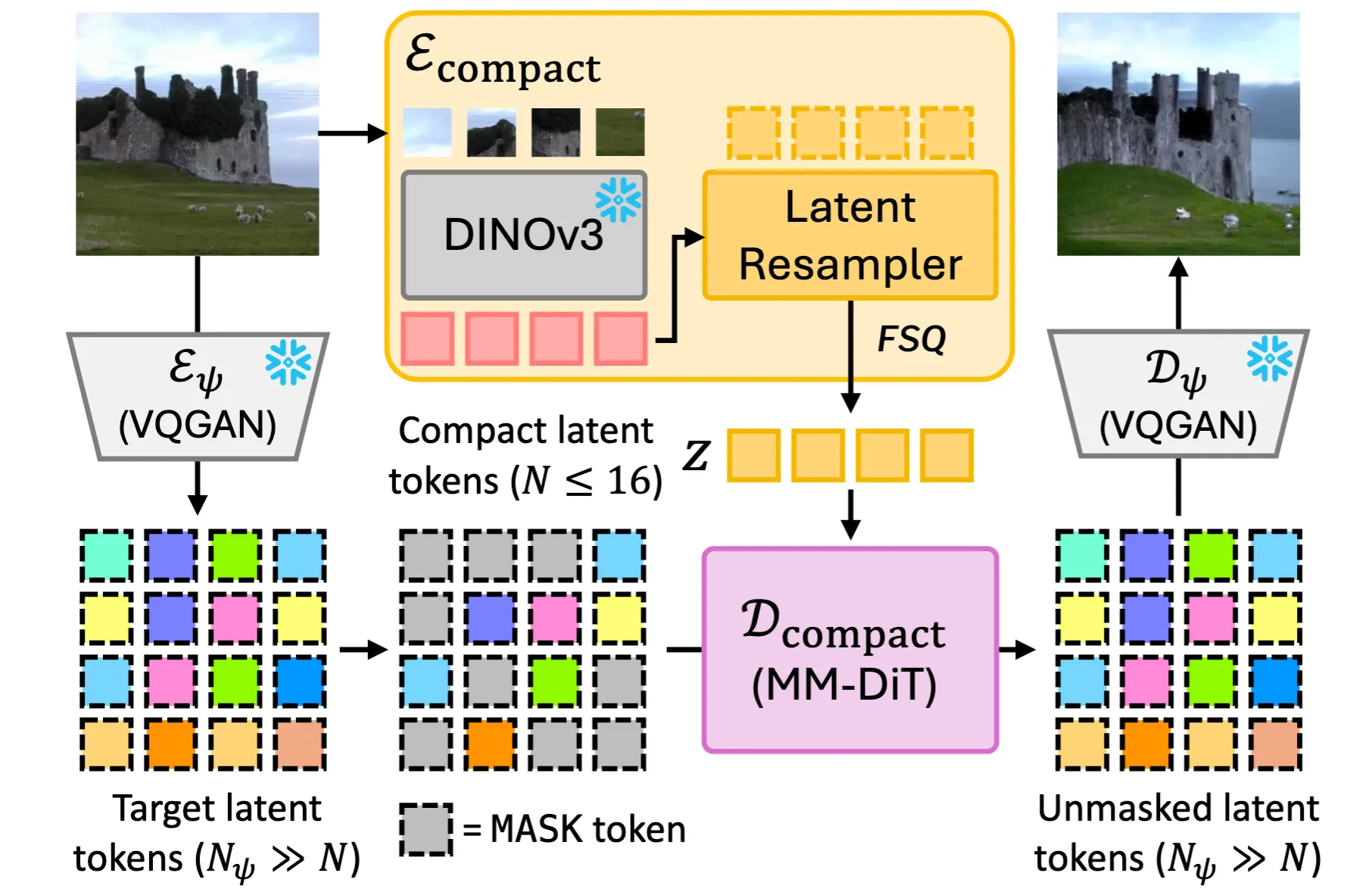
Now, we enable the tokenizer to compress an image into an even more aggresive level: 8 tokens!
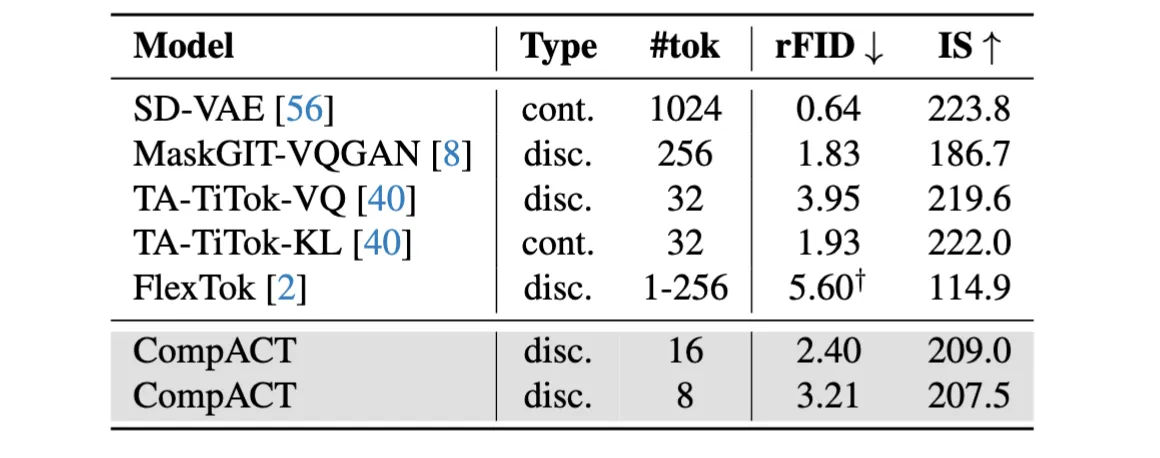
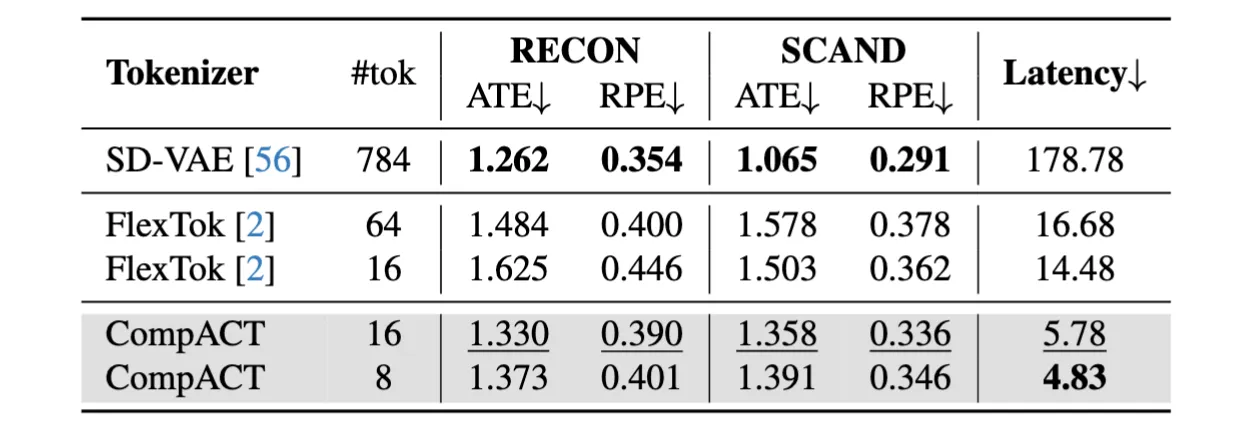
And it achieves comparable planning performance with dramatically faster speed.
What do CompACT tokens capture?

The tokens now tend to understand the image input in a compositional way: it captures semantical instances: the salient animal, buildings, and robot gripper/objects. Note that this property solely emerged from tokenizer’s reconstruction training!
Abstract
World models provide a powerful framework for simulating environment dynamics conditioned on actions or instructions, enabling downstream tasks such as action planning or policy learning. Recent approaches leverage world models as learned simulators, but its application to decision-time planning remains computationally prohibitive for real-time control. A key bottleneck lies in latent representations: conventional tokenizers encode each observation into hundreds of tokens, making planning both slow and resource-intensive. To address this, we propose CompACT, a discrete tokenizer that compresses each observation into as few as 8 tokens, drastically reducing computational cost while preserving essential information for planning. An action-conditioned world model that occupies CompACT tokenizer achieves competitive planning performance with orders-of-magnitude faster planning, offering a practical step toward real-world deployment of world models.