.png)

Abstract
Generalized referring image segmentation (RIS) aims to segment regions in an image described by a natural language expression, handling not only single-target but also no- and multi-target scenarios. Previous approaches have proposed new components that enable a conventional RIS model to handle these additional scenarios, such as a target presence prediction head for no-target scenarios and multiple mask candidates for multi-target cases. However, we observe that
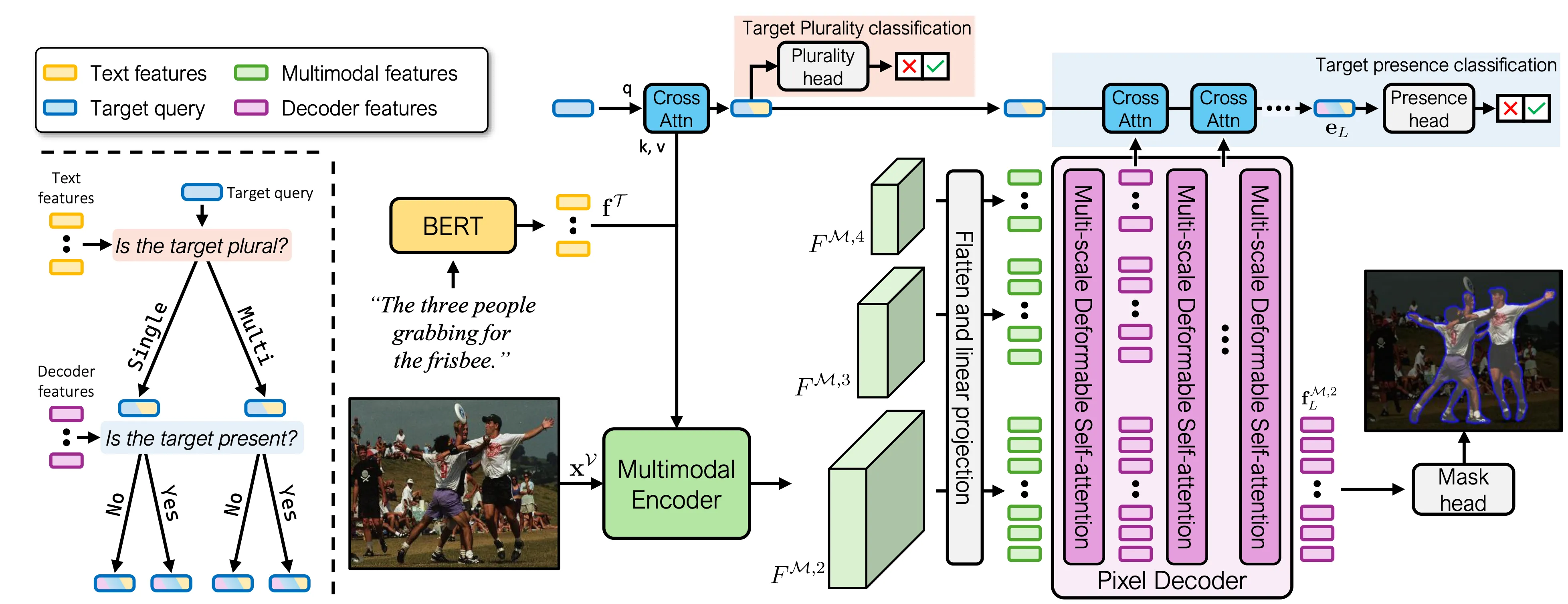
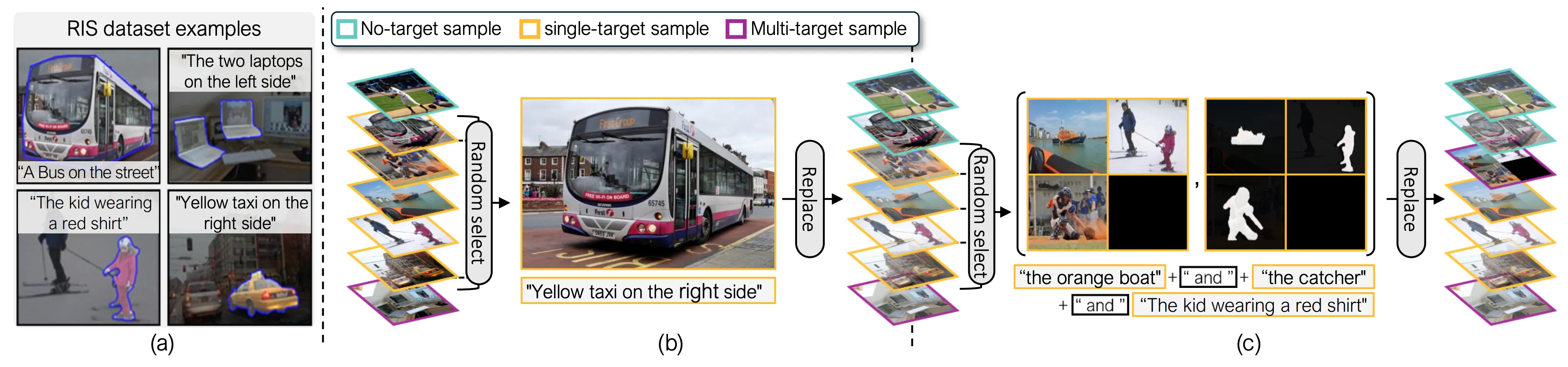
these methods predominantly rely on the conventional RIS backbone without fully integrating the additional components and thus still struggle in such general scenarios. To address this, we propose an effective framework specifically tailored to handle no-target and multi-target scenarios, incorporating both architectural and data-driven approaches. Our architecture employs a learnable query designed to understand both target presence and plurality. While this approach alone outperforms previous state-of-the-art methods with similar computational
requirements, we further introduce a novel data augmentation strategy that enables our framework to surpass computationally intensive LMM-based approaches.
POSTER:
